一图道破大端序和小端序的区别
在裘宗燕翻译的《程序设计实践》里,这对术语并没有翻译为“大端”和小端,而是“高尾端”和“低尾端”,这就好理解了:如果把一个数看成一个字符串,比如11223344看成“11223344”,末尾是个'\0‘,’11‘到’44'个占用一个存储单元,那么它的尾端很显然是44,前面的高还是低就表示尾端放在高地址还是低地址,它在内存中的放法非常直观,如下图:
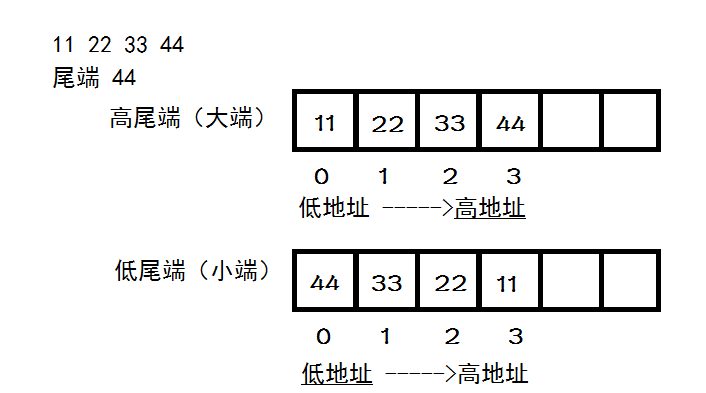
这两种字节序没有标准可循,都有系统在使用。把某个给定系统所用的字节序称为主机字节序。
检测主机字节序的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | #include <stdlib.h> #include <stdio.h> int main(int argc, char **argv) { union { short s; char c[sizeof(short)]; } un; un.s = 0x0102; if(sizeof(short)==2) { if(un.c[0]==1 && un.c[1] == 2) printf("big-endian\n"); else if (un.c[0] == 2 && un.c[1] == 1) printf("little-endian\n"); else printf("unknown\n"); } else printf("sizeof(short)= %d\n",sizeof(short)); exit(0); } |
这里补充一下C语言中的union相关的知识,C不熟的同学做个参考:
union为联合体,其中的数据成员公用同一块内存地址,union所占的内存块的大小,由占用内存空间最大的数据成员决定。
因为公用同一块内存地址,所以对其中的一个数据成员赋值,会覆盖其他数据成员的内容。
举例上述代码中的union,对s变量赋值,则可以通过c访问到s的值,同样,如果对c的内容做修改,会覆盖掉s的值。